Deployment architecture for Sensu
This guide describes various planning considerations and recommendations for a production-ready Sensu deployment, including details related to communication security and common deployment architectures.
etcd is a key-value store that is used by applications of varying complexity, from simple web apps to Kubernetes. The Sensu backend uses an embedded etcd instance for storing both configuration and observability event data, so you can get Sensu up and running without external dependencies.
By building atop etcd, Sensu’s backend inherits a number of characteristics to consider when you’re planning for a Sensu deployment.
Create and maintain clusters
Sensu’s embedded etcd supports initial cluster creation via a static list of peer URLs. After you create a cluster, you can add and remove cluster members with etcdctl tooling.
If you have a healthy clustered backend, you only need to make Sensu API calls to any one of the cluster members. The cluster protocol will replicate your changes to all cluster members.
Read Run a Sensu cluster and the etcd documentation for more information.
Hardware sizing
Because etcd’s design prioritizes consistency across a cluster, the speed with which write operations can be completed is very important to the Sensu cluster’s performance and health. This means that you should provision Sensu backend infrastructure to provide sustained input/output operations per second (IOPS) appropriate for the rate of observability events the system will be required to process.
To maximize Sensu Go performance, we recommend that you:
- Follow our recommended backend hardware configuration.
- Implement documented etcd system tuning practices.
- Benchmark your etcd storage volume to establish baseline IOPS for your system.
- Scale event storage using PostgreSQL to reduce the overall volume of etcd transactions.
Communications security
Whether you’re using using a single Sensu backend or multiple Sensu backends in a cluster, communication with the backend’s various network ports (web UI, HTTP API, WebSocket API, etcd client and peer) occurs in cleartext by default. We recommend that you encrypt network communications via TLS, which requires planning and explicit configuration.
Plan TLS for etcd
The URLs for each member of an etcd cluster are persisted to the database after initialization. As a result, moving a cluster from cleartext to encrypted communications requires resetting the cluster, which destroys all configuration and event data in the database. Therefore, we recommend planning for encryption before initiating a clustered Sensu backend deployment.
WARNING: Reconfiguring a Sensu cluster for TLS post-deployment will require resetting all etcd cluster members, resulting in the loss of all data.
As described in Secure Sensu, the backend uses a shared certificate and key for web UI and agent communications. You can secure communications with etcd using the same certificate and key. The certificate’s Common Name (CN) or Subject Alternative Name (SAN) must include the network interfaces and DNS names that will point to those systems.
NOTE: As of Go 1.15, certificates must include their CN as an SAN field. To prevent connection errors, follow Generate certificates to make sure your certificates’ SAN fields include their CNs.
Read Run a Sensu cluster and the etcd documentation for more information about TLS setup and configuration, including a walkthrough for generating TLS certificates for your cluster.
Common Sensu architectures
Depending on your infrastructure and the type of environments you’ll be monitoring, you may use one or a combination of these architectures to best fit your needs.
Single backend (standalone)
The single backend (standalone) with embedded etcd architecture requires minimal resources but provides no redundancy in the event of failure.

Single Sensu Go backend or standalone architecture
You can reconfigure a single backend as a member of a cluster, but this operation requires destroying the existing database.
The single backend (standalone) architecture may be a good fit for small- to medium-sized deployments (such as monitoring a remote office or datacenter), deploying alongside individual auto-scaling groups, or deploying in various segments of a logical environment spanning multiple cloud providers.
For example, in environments with unreliable WAN connectivity, having agents connect to a local backend may be more reliable than having agents connect over WAN or VPN tunnel to a backend running in a central location.
Clustered deployment for single availability zone
To increase availability and replicate both configuration and data, join the embedded etcd databases of multiple Sensu backend instances together in a cluster. Read Run a Sensu cluster for more information.
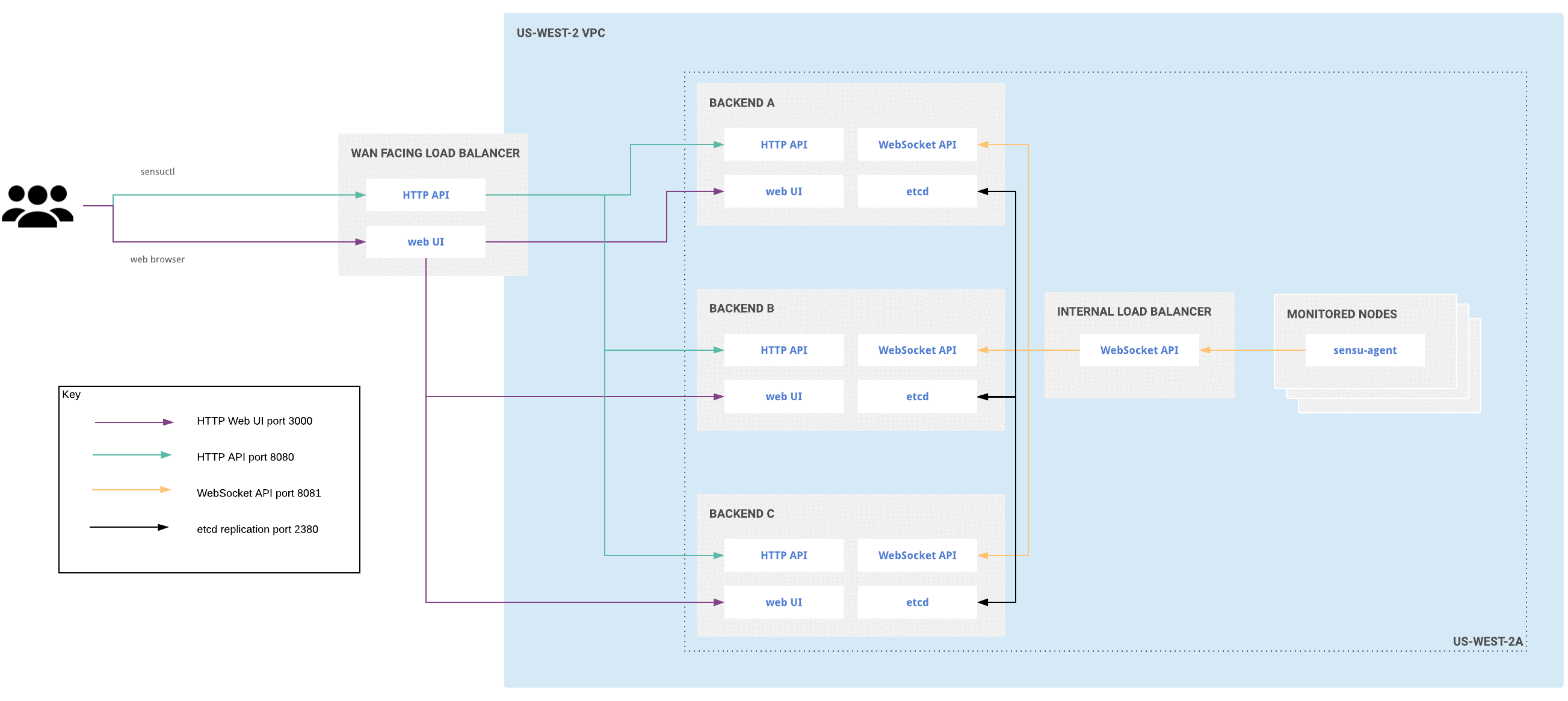
Clustered Sensu Go architecture for a single availability zone
Clustering requires an odd number of backend instances. Although larger clusters provide better fault tolerance, write performance suffers because data must be replicated across more machines. The etcd maintainers recommend clusters of 3, 5, or 7 backends. Read the etcd documentation for more information.
Clustered deployment for multiple availability zones
Distributing infrastructure across multiple availability zones in a given region helps ensure continuous availability of customer infrastructure in the region if any one availability zone becomes unavailable. With this in mind, you can deploy a Sensu cluster across multiple availability zones in a given region, configured to tolerate reasonable latency between those availability zones.
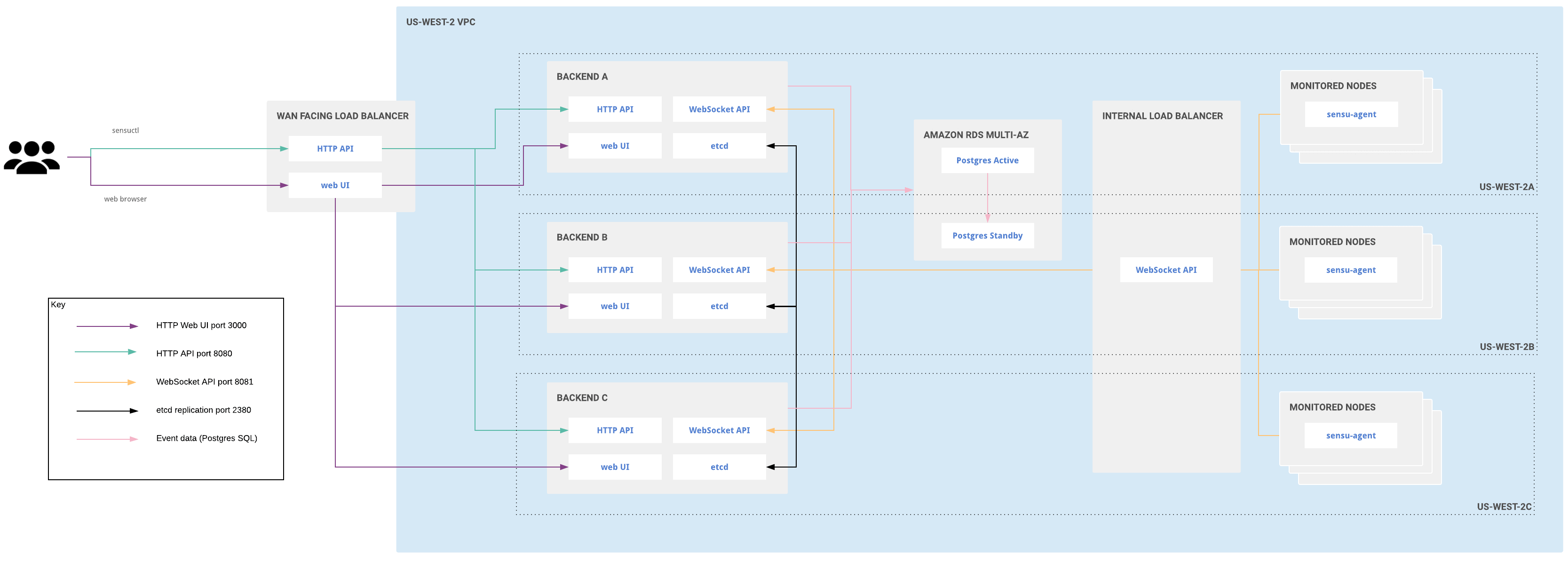
Clustered Sensu Go architecture for multiple availability zones
Large-scale clustered deployment for multiple availability zones
In a large-scale clustered Sensu Go deployment, you can use as many backends as you wish. Use one etcd node per availiability zone, with a minimum of three etcd nodes and a maximum of five. Three etcd nodes allow you to tolerate the loss of a single node with minimal effect on performance. Five etcd nodes allow you to tolerate the loss of two nodes, but with a greater effect on performance.
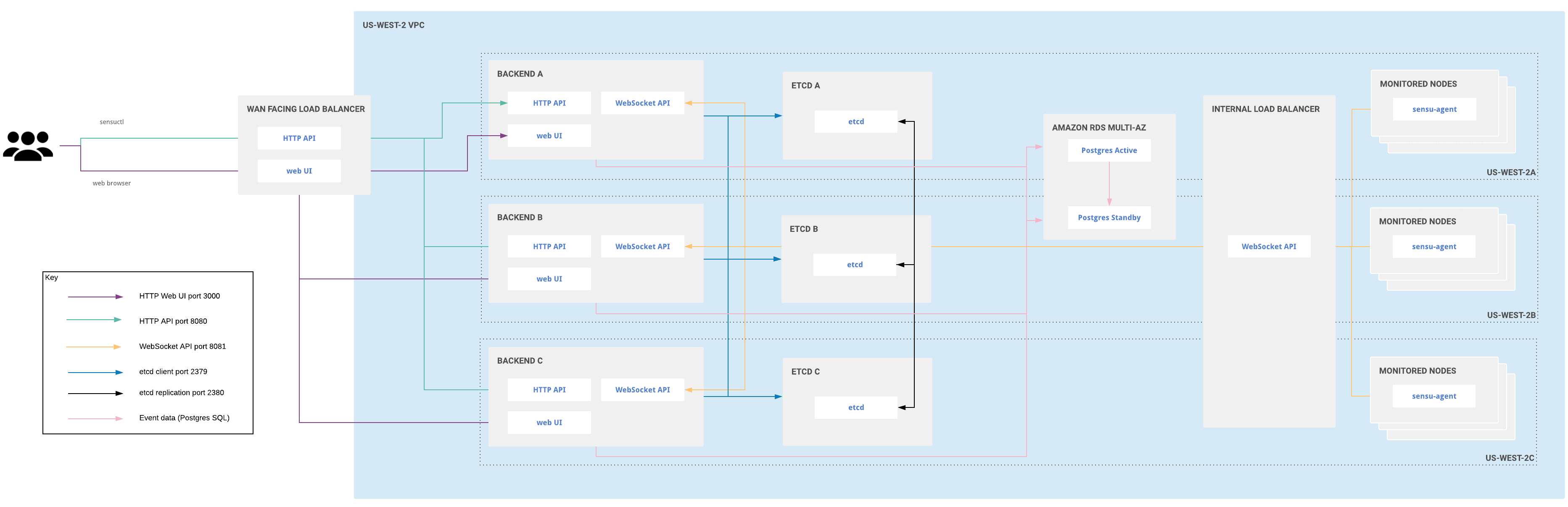
Large-scale clustered Sensu Go architecture for multiple availability zones
Scaled cluster performance with PostgreSQL
To achieve the high rate of event processing that many enterprises require, Sensu supports PostgreSQL event storage as a commercial feature. Read the datastore reference to configure the Sensu backend to use PostgreSQL for event storage.
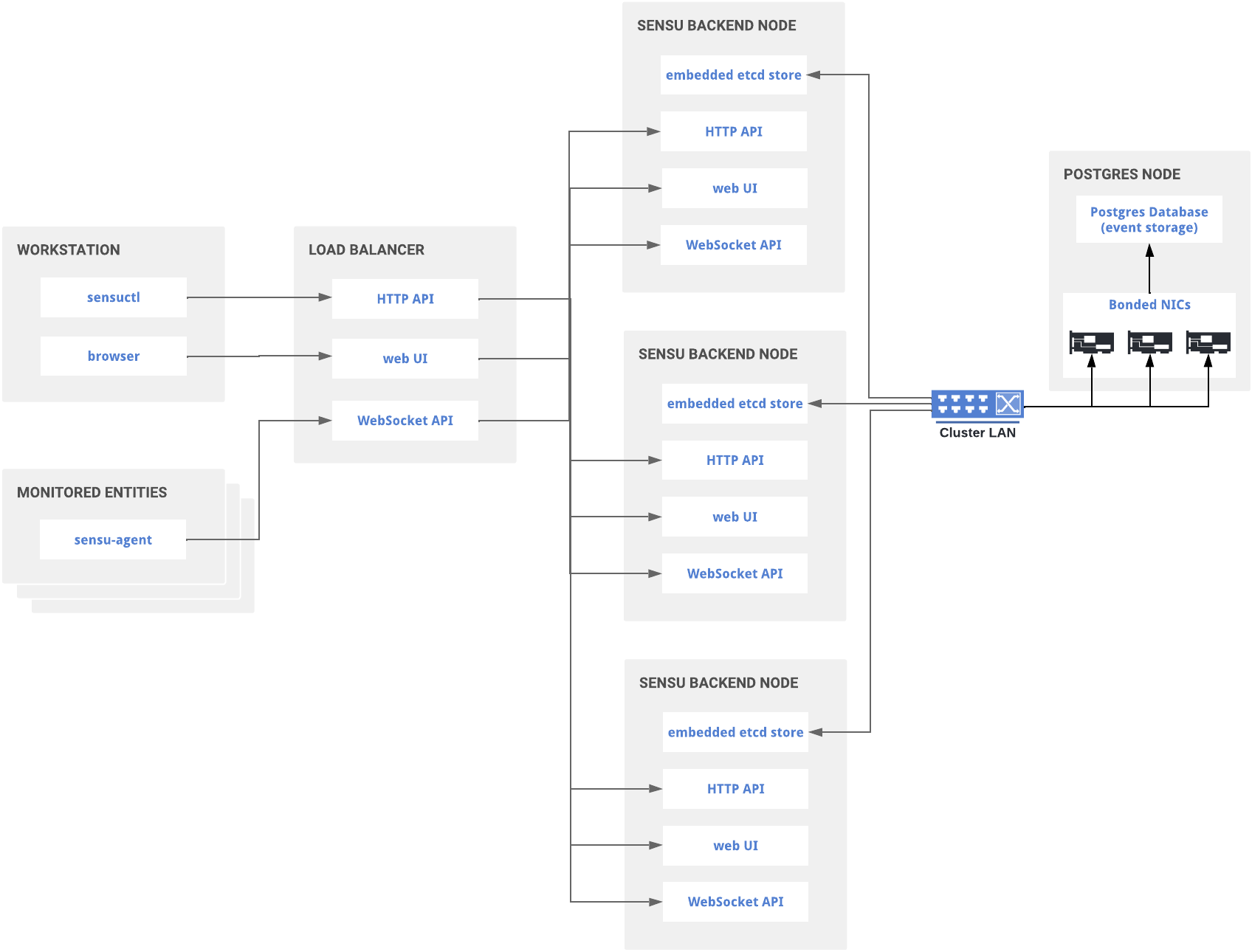
Clustered Sensu Go architecture with PostgreSQL event storage
In load testing, Sensu Go has proven capable of processing 36,000 events per second when using PostgreSQL as the event store. Review the sensu-perf project repository for a detailed explanation of our testing methodology and results.
Large-scale cloud deployment for multiple regions
In a large-scale cloud deployment for multiple regions, place all backends, etcd nodes, and event datastores in a single region. The backends communicate with agents in other regions via WebSocket transport. This configuration allows you to load-balance traffic between the backends in the main regions and the agents in other regions.
NOTE: Do not use read replicas in a cloud deployment. Sensu is write-heavy, and the brief, unavoidable replication delays will cause inconsistency between etcd data and PostgreSQL data.
This diagram depicts an example architecture for a Google Cloud Platform (GCP) deployment, but you can reproduce this architecture with your preferred cloud provider:
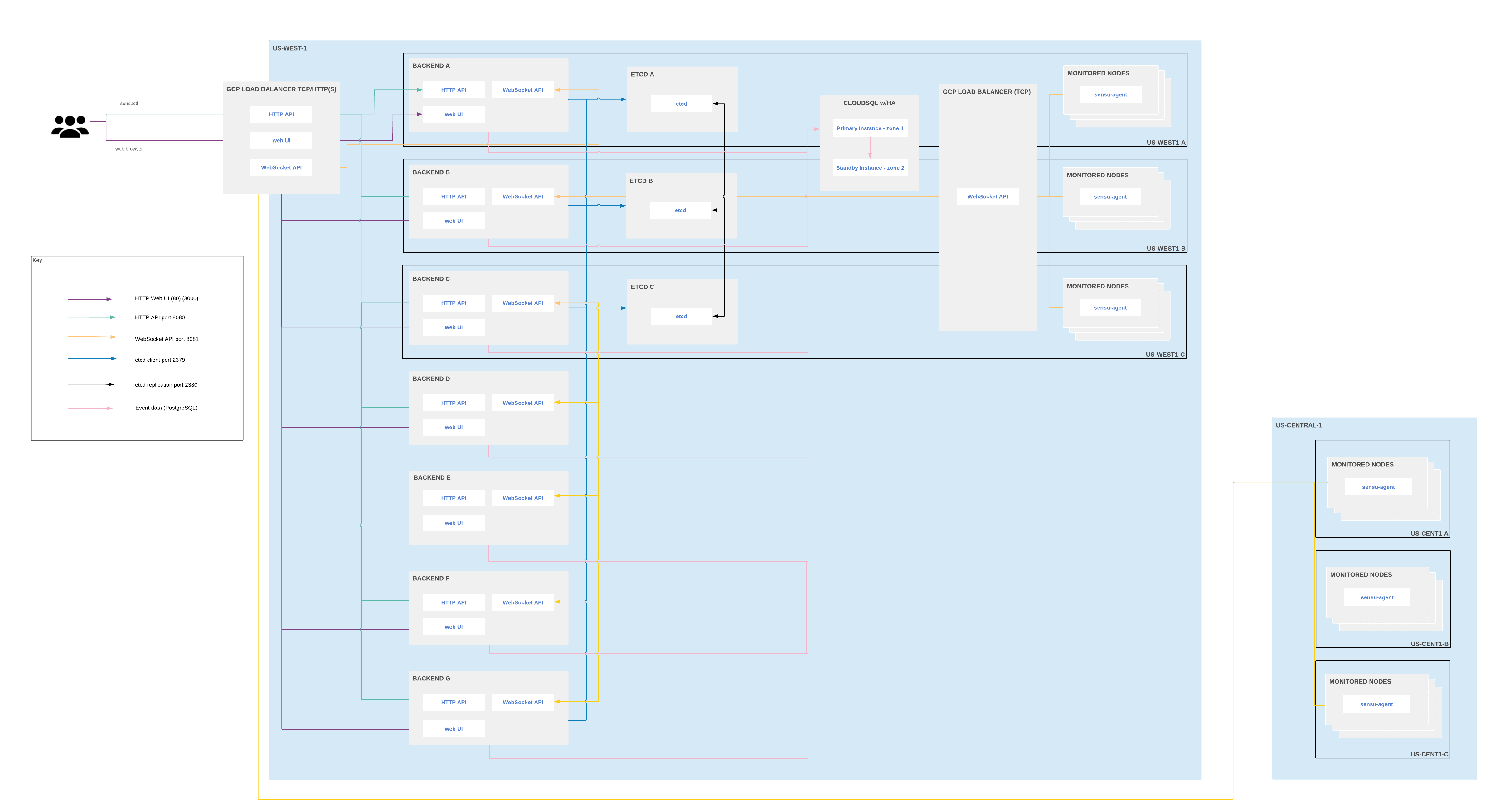
Example Sensu Go architecture for multi-region cloud deployments
In this example, the load balancer translates traffic on port 80 to port 3000 so that users do not need to include :3000 in the web UI URL.
API traffic is load-balanced to the backends as well.
Architecture considerations
Networking
Clustered deployments benefit from a fast and reliable network. Ideally, they should be co-located in the same network segment with as little latency as possible between all the nodes. We do not recommend clustering backends across disparate subnets or WAN connections.
Although 1GbE is sufficient for common deployments, larger deployments will benefit from 10GbE, which allows a shorter mean time to recovery.
As the number of agents connected to a backend cluster grows, so will the amount of communication between members of the cluster required for data replication. With this in mind, clusters with a thousand or more agents should use a discrete network interface for peer communication.
Load balancing
Although you can configure each Sensu agent with the URLs for multiple backend instances, we recommend that you configure agents to connect to a load balancer. This approach gives operators more control over agent connection distribution and makes it possible to replace members of the backend cluster without updates to agent configuration.
Conversely, you cannot configure the sensuctl command line tool with multiple backend URLs. Under normal conditions, sensuctl communications and browser access to the web UI should be routed via a load balancer.
Load balancing algorithms
If the load balancer uses round robin mode, when an agent comes online, the load balancer sends the agent’s traffic to whichever backend is next in the pattern, regardless of load. This can result in slow load balancing among backends, especially after restarting a backend.
In least connection mode, the load balancer sends new agent traffic to the backend with the least traffic. This helps to evenly distribute the load among backends more quickly.